
特征工程,一文读懂近实时特征工程


前言在上一篇《基于中心化元数据及配置驱动的特征工程管理平台》中(点击可跳转),重点介绍了eBayAI特征平台如何通过统一的元数据和配置驱动,为用户提供了快速发现特征、开发新特征以及对开发的特征进行生命周期管理的能力。站在平台的角度,为了实现这样目标,除了对元数据本身的管理之外,作为平台的计算层也需要具备相应的能力。eBayAI特征平台的
前言
在上一篇《基于中心化元数据及配置驱动的特征工程管理平台》中(点击可跳转),重点介绍了eBay AI特征平台如何通过统一的元数据和配置驱动,为用户提供了快速发现特征、开发新特征以及对开发的特征进行生命周期管理的能力。站在平台的角度,为了实现这样目标,除了对元数据本身的管理之外,作为平台的计算层也需要具备相应的能力。eBay AI特征平台的计算层分为离线和近实时(Near Real-Time, NRT)两部分,本文主要介绍近实时特征工程相关的设计和实现。
背景
近年来,随着业界不断的创新和探索,机器学习在业务中承担的角色越来越重要。除了模型算法本身之外,良好的预测效果离不开特征的选择。从特征的来源看,通常可以分为3种类型:
- 离线特征
- On-the-fly特征
- 近实时特征
数据科学家开发特征时往往先从离线特征开始,因为离线特征的数据源基本来自数据仓库或者是数据湖,这些都是数据科学家非常熟悉的。但离线特征最大的问题是数据有较长延迟。通过一系列ETL任务把数据导入到数据仓库或者是数据湖,在进行离线特征计算,往往会有一天或以上的数据延迟。
当需要延迟更低的特征时,数据科学家往往需要在线应用开发工程师的帮助,来开发在线计算的特征,我们将它们称为on-the-fly特征。On-the-fly特征好处是数据非常实时,但在实际运用中也有不小的问题:
数据科学家对于在线数据往往太不熟悉,需要工具和方法帮助他们在线下发现,探索在线数据的元数据和数据质量;
需要知识的传递,把特征计算的逻辑转递给在线应用开发工程师来进行开发,而此时这些特征是否真的有用还无法确认;
需要在线应用开发工程师记录特征的结果,并dump到线下进行累计,才能用于真正的模型训练,来确认特征是否真的有用。
总而言之,on-the-fly特征成本很高,TTM(Time-to-market)很长,并且特征可重用性也相对比较差。
由于离线特征和on-the-fly特征的种种限制,近来业界不约而同地把更多的投资放到了流式特征工程上,也就是我们通常说的近实时特征。近实时特征通常是基于事件,进行流式数据处理来生成特征,并将相应的特征指存储到Key/value存储上。它综合了离线特征和on-the-fly特征的好处,数据有着较低的延迟并且非常容易被重用。
挑战
在eBay内部,原先的模型通常都是基于天级别的离线特征。随着越来越多的模型预测依赖NRT的特征,一些团队开始尝试构建NRT特征工程。
具体可以分为以下几步:
- 数据科学家使用实时的用户行为或者事务变化作为数据源;
- 数据科学家或数据工程师会将实时数据dump到离线数据仓库,开发离线特征的计算逻辑,生成离线特征。通常这个过程使用Spark任务完成;
- 在特征正式写入在线特征仓库(Online Feature Store)之前,数据科学家进行离线模型的训练和评估;
- 通过离线训练模型和评估后,数据科学家或数据工程师需要开发实时特征的计算逻辑,生成实时特征。通常这个过程使用Flink任务完成。
上面的方案已经可以解决NRT从无到有的问题,但是从用户、工程效率等角度看
依然存在一些挑战:
- 由于方案都是针对某一个具体场景实现的,很难扩展到新的场景。数据科学家在开发新的特征时,通常需要创建新的Pipeline,包括离线的Spark任务以及实时的Flink任务,对数据科学家提出了很高的工程技术要求。另外,由于每次都需要创建新的Pipeline,无法保证数据的正确性,一个新的特征从开发、测试到上线需要花费大量的时间;
- 缺乏自服务方式,让数据科学家不依赖其他工程师的情况下,发现、重用并测试别人已开发的特征,或者独立开发、定义、测试直到发布他所开发的近实时特征;
- 通常离线的数据源是数仓,在线的数据源是Kafka,不同的数据源很难保证数据是一致的;另外,离线和实时采用不同的技术栈,可能分别由不同团队负责,难以保证离线和在线的计算逻辑是一致的;
- 独立的Pipeline带来了一定的隔离性,但是随着业务的增加,大量的Pipeline缺少统一的元数据管理和管控,对资源、监控报警、运维等带来很大的压力;
- 缺少point-in-time的特征模拟能力;
- 缺少完整的生命周期管理,包括离线、在线数据源的选取,特征的测试、上线和下线等。
平台化的价值
如上所述,NRT特征工程的实现是相当复杂的。从平台建设的角度看,首要目标是帮助用户快速的完成特征开发和上线。考虑到在机器学习场景中,80%的场景都是使用简单的特征。因此,在权衡复杂性和工程化之后,为了最大化的体现平台优势,eBay NRT特征工程决定对80%的简单特征做到大规模简单化,对20%的复杂特征提供相应的自定义扩展能力。优先支持的2种简单类型的NRT特征:
Roll-up类型:Roll-up类型的特征是机器学习中最常见的特征类型。如计算某一时间区间的商品点击数、近期的用户行为日志等。NRT特征工程内置实现了两种类型的Roll-up特征:
- 滑动窗口(Sliding Window)
- LastK
Embedding类型:主要服务于eBay的视频、图像、NLP等业务。Embedding类型的特征处理过程与Roll-up大致相同,不同之处在于Embedding类型的特征需要调用在线模型预测生成。对于这样的需求,可以采用DSL+UDF的方式实现,DSL定义特征的计算逻辑,UDF实现模型调用。
基于UI可以实现简单特征的快速开发和上线:
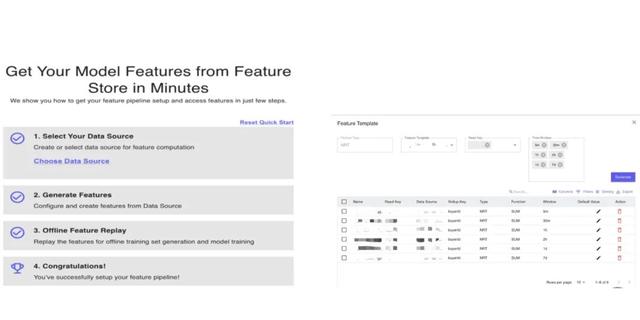

eBay NRT 特征工程
设计原则
基于以上的挑战和痛点,eBay NRT特征工程遵循以下的设计原则
让数据科学家自助式的进行特征开发:
- 基于统一的配置和元数据管理,用户可以快速的发现和重用数据源及特征,避免重复计算;
- 采用统一的DSL开发语言,确保在线/离线计算逻辑强一致,降低开发和测试成本。并支持point-in-time特征模拟;
- 基于通用的NRT Pipeline和元数据驱动,用户可以快速完成特征开发,无需代码变更和发布,避免烟囱式开发和大量任务的管理维护;
- 支持特征的回填(Backfill),降低特征准备时间,提供快速的TTM;
- 全生命周期的统一管控,支持数据血缘和计算依赖的可视化,降低变更导致的风险。
整体架构
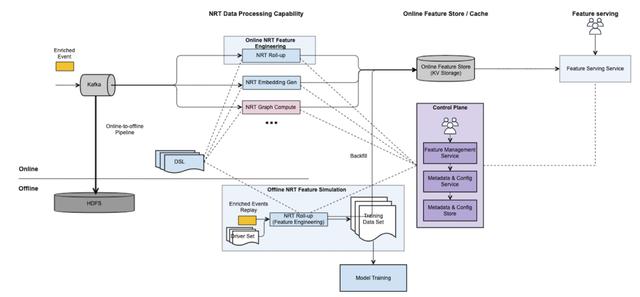
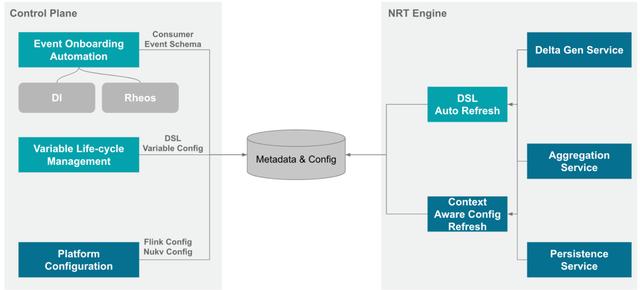
NRT特征工程包含以下几部分:
- 数据源:考虑到数据的预处理需要业务领域的知识,比如过滤、字段转换等。因此NRT特征工程处理的是经过业务部门处理过的数据源。为了保证在线和离线的数据一致,NRT特征工程借助DI团队提供的在线到离线的转存服务,将Kafka中的实时数据存储到HDFS中,作为离线数据源。
- 在线NRT特征处理:实时从特征管理平台获取数据源、Consumer和DSL等元数据,自动地实时消费Kafka中的数据。对于每一个Kafka消息,计算DSL并将计算结果写入在线特征仓库。
- 离线NRT特征模拟:与在线NRT特征处理类似,从特征管理平台获取实时数据源对应的离线表、DSL、驱动数据集等元数据。通过回放历史数据的方式,生成训练数据集,提供给后续的模型训练使用。对于同一个特征,离线和在线执行相同的DSL,保证离线和在线产出的特征是一致的。
- 在线特征仓库和查询服务:NRT特征最终会以KV的形式存储。考虑到存储的成本问题,特征在写入时会进行压缩。由于用户无法直接使用在线特征仓库中的数据,因此eBay NRT特征工程提供了查询服务,用户只需通过DSL定义需要的特征,查询服务会自动从特征管理平台获取相应的元数据,并在用户查询时解压、执行DSL以及一系列优化工作。关于在线特征仓库部分后续会有相关的文章详细介绍。
Roll-up 特征实现
无论是Roll-up特征、Embedding特征还是其他类型的特征。eBay NRT特征平台都是采用通用的架构体系去实现的。为了描述方便,本文将重点介绍Roll-up类型的特征是如何实现的。
计算过程
我们将Roll-up类型的特征抽象成两部分:State和Delta。State代表Roll-up特征的状态,Delta表示一个Roll-up的增量更新。基本的Roll-up过程可以描述为State + Delta,即Delta应用到State生成一个新的State。基于这样的抽象,具体的计算过程可以分为3个阶段:
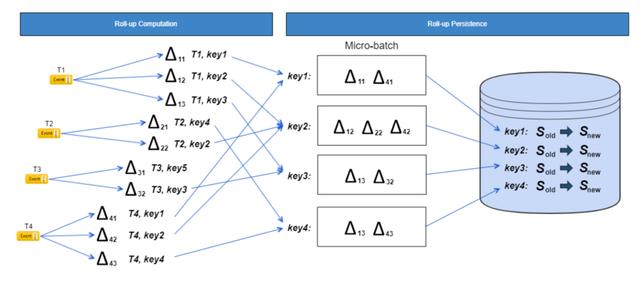
计算Delta阶段:通过一个分布式服务并行消费Kafka Topic。考虑到保证事件的顺序需要花费很大的代价,Roll-up特征在设计时支持Delta的乱序。因此对于Kafka Topic中的事件,没有顺序性的要求,相同key的事件可以在不同的partition中。整个计算过程是无状态的;
聚合阶段:根据key进行shuffle,保证相同key的delta和state在同一个地方计算,防止并发导致的结果丢失。同时支持对一定时间内的Delta进行预集合,减少对下游系统的操作,提高吞吐;
存储阶段:将新的State通过存储服务写入NuKV存储中。为了保证数据的一致性,存储服务并未使用eBay内部服务标准的3数据中心部署,采用Active-Standby的部署模式,保证相同的key不会在多个数据中心并行处理。
存储变量
如《基于中心化元数据及配置驱动的特征工程管理平台》所述,我们将特征抽象成两部分:存储变量(Stored Variable)和特征模版(Feature Template)。Roll-up特征的存储变量在设计时重点考虑了如下几个问题:
存储粒度,以便支持不同时间粒度的特征查询;
预处理,如去重、排序等,提升特征查询的SLA;
更新幂等,以便支持回填操作,降低特征上线准备时间。
滑动窗口存储变量
从访问模式、数据压缩/局部性以及键/值记录数量等考虑,目前滑动窗口存储变量采用的存储数据模型如下所示:
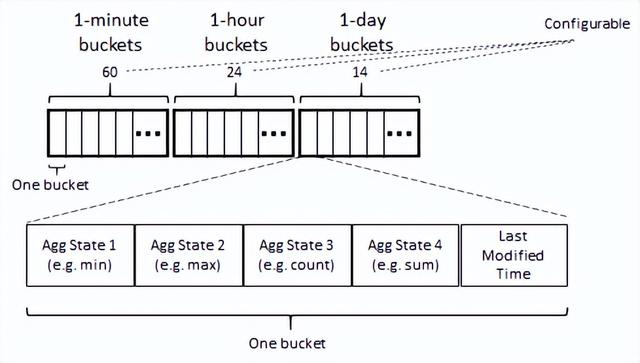
根据不同的需求,滑动窗口存储变量会包含不同时间粒度的桶。通常会包含天级别、小时级别和分钟级别。小时级别和分钟级别的桶数量是固定的,分别为24和60。天级别的桶数量和特征定义相关,如需要近7天的特征值,则天级别的桶数量至少为7。在桶内部,会保存所有的聚合结果,如min、max、count等。
基于这样的数据模型,可以很容易满足以下场景:
根据给定的参数选择合适粒度的桶,得到不同时间粒度的特征。如读取最近5天的累加值,则查询近5天天粒度的桶并累加计算即可;
支持不同的聚合函数,在写入阶段预聚合,方便快速查询;
对于新的Delta,首先确定对应的桶,判断桶的最后修改时间,如果早于一定的时间,则重新计算桶的值,实现写入幂等,并以此支持回填功能。
LastK存储变量
LastK存储变量用来维护一个记录列表。每条记录可以包含单个或多个字段。默认情况下,如果记录中没有定义point-in-time时间戳,则会自动添加。
LastK变量列表中的记录默认按point-in-time时间戳排序(升序)。如果记录数超过配置的最大值,则最旧的记录将被删除。此外,支持用户定义一个去重字段,使得具有相同去重值的多条记录将被去重为一条记录,并且时间戳将被更新为最新的一条。
基于LastK存储的记录列表,可以灵活地进行各类计算,如记录过滤、分组、聚合等。
典型的场景包括:
按时间排序的事件系列,可以支持 LSTM等深度学习模型;
基于最新K个事件的各类计算。
实例
下面将以一个记录用户浏览记录的特征为例,描述如何通过DSL快速创建一个特征。特征定义为:
提供用户最近200次页面浏览时长
包含相关的pageId及其itemId
具体可以分为以下几步:
首先,我们声明一个LastK存储变量page_view_userid并定义它的schema。变量最大值设置为200,字段信息包括itemId、pageId和timestamp;
define LastK variable page_view_userid {
metadata : {
"keyDimension" : "UserId",
"maxSize" : "200",
"dedupFields" : "[\"pageId\",\"pit\"]",
"fieldsInfo" : "[
{\"name\":\"pit\",\"type\":\"long\",\"description\":\"Point-in-time timestamp\"},
{\"name\":\"itemId\",\"type\":\"string\",\"description\":\"Item ID\"},
{\"name\":\"pageId\",\"type\":\"long\",\"description\":\"Page ID\"}
]",
"description" : "page_view_userid"
};
};其次,我们定义Delta计算逻辑。该变量使用数据源PageViewEvent。对于每个事件,我们提取 itemId和pageId;
process variable page_view_userid as any{
process PageViewEvent {
local record = map{
"itemId" : @evt.itemId,
"pageId" : @evt.pageId
};
@lastKDelta(@evt.eventTimestamp, @evt.userId, record);
};
};第三,我们在特征模板 page_view_
duration_userid 中定义读取逻辑。可以看到我们从 LastK 变量中获取了页面浏览列表。然后我们遍历列表,通过
next.pit – cur.pit 计算页面浏览时长。
define variable page_view_duration_userid(long pit, KeyDim.UserId userId) as list<map<string,any>> {
metadata : {
"description" : "sequence of page view and duration"
};
local sequence = [];
local ls = @lastKLoad(userId, "page_view_userid", pit);
for(local i =0;i<ls.size()-1;i=i+1){
local cur = ls.get(i);
local next = ls.get(i+1);
local dur = next.pit-cur.pit;
local enriched = map {
"itemId" : cur.itemId,
"pageId" : cur.pageId,
"userId" : userId,
"pageViewDuration" : dur
};
sequence.add(enriched);
};
sequence;
};在定义DSL之后,将进行离线模拟,验证和评估之后最终将它们发布到生产中。最后,可以通过在线特征仓库中获取用户的页面浏览时长
:page_view_duration_userid^userId。以上所有功能都可以在特征管理平台自助完成。
平台化建设
基于以上的核心设计,完全可以构建一个通用的NRT特征计算服务。但是,作为eBay AI的基础平台,承载着eBay内部大量NRT特征的开发和生成,因此对于整个平台的SLA、功能的完备程度都提出了极高的要求。
元数据集成
特征管理平台提供了特征的全生命周期管理能力。为了实现元数据驱动的目标,NRT特征工程与特征管理平台做了紧密的集成。支持特征的模拟、发布和下线。
NRT特征工程的各个组件都集成了配置和DSL加载器,当用户发布新的特征后,各个组件会实时的获取相关的元数据,自动完成特征的计算和存储。此外,当用户下线某一个特征时,各个组件也会及时获取最新的元数据,停止对该特征的计算。
扩展性及高可用
NRT特征工程中的各个组件都具备灵活的横向扩展能力。如在Roll-up类型的特征计算过程中,负责Delta计算的组件需要消费很多Kafka Topic,可以根据总体的消息量和系统的水位情况,做横向的扩展。对于有特殊要求的业务,还可以依赖特征管理平台的流水线的能力,单独创建一个集群进行处理。
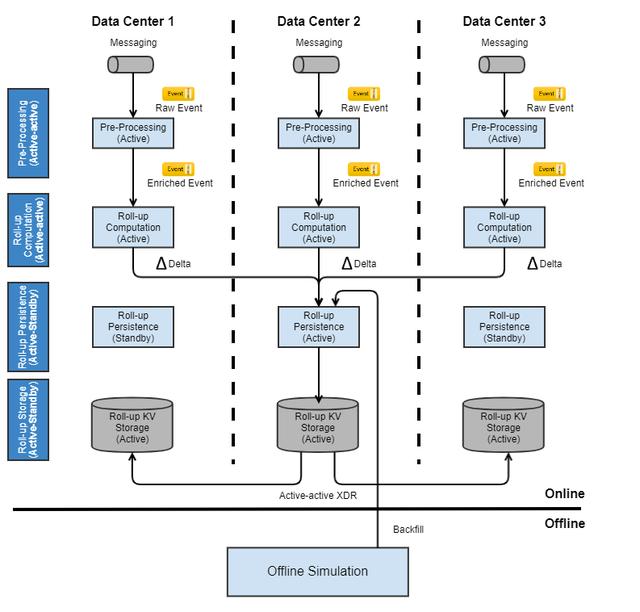
NRT特征工程采用标准的3机房部署,具备高可用能力。下图为Roll-up计算的多机房部署架构。由于计算Delta是无状态的,采用Active-Active的部署模式。Delta聚合使用Apache Flink计算引擎,由于是有状态的计算,采用Active-Standby部署模式。当开启高可用模式之后,Rheos平台(eBay内部实时计算平台)会定期同步任务状态到其他机房,当Active机房宕机之后,可以在其他机房重新恢复任务。存储服务也是采用Active-Standby部署模式,避免并行操作可能带来的数据一致性问题。
错误处理
在NRT的特征计算中,错误是不可避免的。导致错误的原因有很多,比如基础服务异常、网络抖动、外部服务宕机等都有可能导致错误的发生。在处理错误时,需要权衡特征的实时性和准确度。对于Roll-up类型的特征,少量的错误对于模型的影响相对较小;对于Embedding类型的特征,发生错误意味着某个对象的丢失,影响较大。因此,对于错误处理,不同的场景需要不同的处理方式:
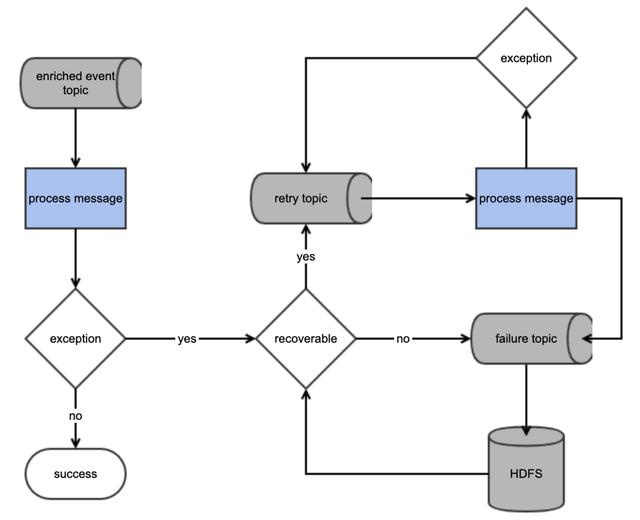
- 在线重试:对于错误容忍度低的场景,当遇到错误时,可以根据错误类型,将错误消息发送到不同的Kafka Topic。对于可恢复的错误,比如网络抖动,可以将消息发送到重试Topic,下游使用一个服务执行相同的DSL进行重试补偿。当达到最大重试次数,将错误消息发送到错误Topic;对于暂时不可恢复的消息,直接将消息发送的错误Topic。将错误Topic中的消息转存到离线HDFS,定时分析错误原因,对于可恢复的错误消息,重新发送到重试队列进行重试补偿。
- 离线回填:对于错误容忍度比较高,接受最终一致性的场景,可以通过T+1的离线数据回填,对错误消息进行补偿。
NRT特征模拟
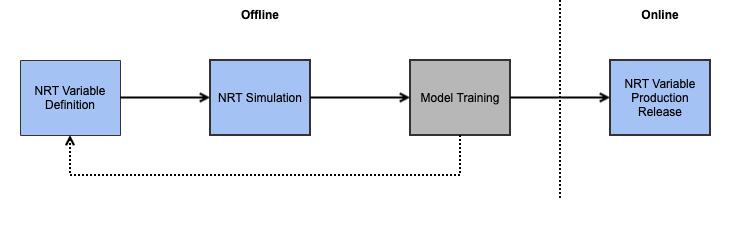
在AI工程中,数据科学家通常需要构造离线训练数据集训练模型,并通过测试数据集对模型和特征进行评估。eBay NRT特征工程基于离线数据的回放,提供了NRT特征的point-in-time模拟能力,帮助用户生成高质量的训练数据集。另外,基于同一套DSL,使得同一个特征在线和离线计算逻辑的强一致,保证了离线评估验证的模型,在使用在线特征后效果是符合预期的。
特征回填
通常一个NRT特征在发布生产之后,会基于最新的事件产出特征,再经过一定时间的积累,才能给模型使用。这个等待的过程依赖模型各自的要求,可能会持续数天,甚至一个月。为了缩短模型上线的时间,NRT特征平台提供了特征回填的功能。得益于存储变量在设计之初就支持了更新的幂等性,通过离线历史数据的回放并更新在线特征即可。以Roll-up类型的特征为例,回填过程如下:
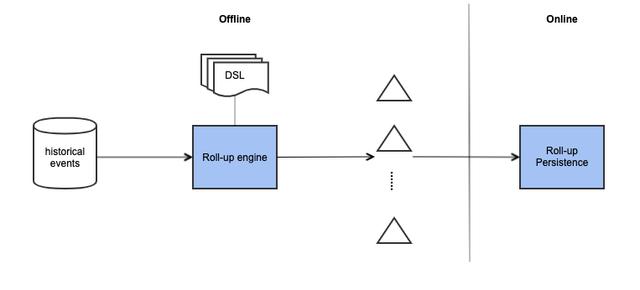
总结和展望
本文主要介绍了eBay AI团队在NRT特征工程中的思路和相关工作。目前已内置支持Roll-up、Embedding等特征,并逐步在往平台化的方向发展。未来我们将在NRT特征工程中支持更多的功能,包括与训练平台、在线预测平台的无缝对接,特征的分析和监控等。
如若转载,请注明出处:https://www.anshangmei.com/29167.html
相关推荐
-
谈储蓄类保单选择逻辑
图片来自于网络《从友邦创赢金生保险计划来谈储蓄类保单选择逻辑》这是馨爸的第100篇保险原创文章作者:馨爸最近高密度接触友邦年金+万能的方案,身边也有朋友选择投保了这款产品,写这篇文章主要是来理清一些理财类保障/储蓄类保
-
为了不踩坑,我查阅相关信息,总结了这份关于手机卡的避坑介绍
“我服了,网上流量卡的名字怎么这么多啊,而且看着套餐内容好像还都一样?”“他们描述的套餐看起来又很便宜,这里面到底有没有坑啊?”在选卡的过程中,很多小伙伴们对这个问题都很费解。我只是想办张卡,要不要这么难啊?一会儿金玉、良缘、青山、绿水、鸟语、花香;一会儿又青龙、白虎、朱雀、玄武、鲲鹏、凤凰的;还有星辰、星空、星河什么的。确实,这些流量卡的名字五花八门,让人眼花缭乱,但是,
-
公积金贷款申请流程需要多长时间
公积金贷款是指通过将个人公积金账户内资金用于贷款申请,实现购房、装修等大额支出的目的。公积金贷款利率低、还款期限长等优点,广受消费者的好评。但是,许多人关心的一个问题是:公积金贷款申请流程需要多长时间?公积金
-
有信用卡必下的网贷2020,有信用卡必下的网贷但是身份证不在身上
2015年4月花呗上线,我知道了先享受后消费的模式,其实先享受后消费的鼻祖是信用卡。1979年10月信用卡问世,解决了我们的当务之急,但是大额的信用卡让我们无法控制自己的物质欲望,让我们从信用卡的“神坛”上摔了下来,信用卡的此时,一些创业者发现了商机,有代还机构和代还APP。那么,信用卡代付机构和APP那么多,我们应该如
-
钱海创投 吴方跃,钱海创投公告
真诚,这是一个难得的品质,也是现代社会中很多人已经具备但是却把他藏起来的品质。我们常常说,一个人的人品好坏与这个是不是真诚的人有直接关系,因为这个人能够真诚对待每个人的话,那么他一定拥有非常好的品质,也是我们常常说的人品不错。但是这个品质却经常被我们不用,原因就是真诚换不来真诚,也有可能是欺骗。我
-
额额我想要,我想要(五)
在师范的生活可以说是惬意,音体美是主科,除添加了教育学、心理学两门课程外,其他科目要求及格就行。和初中时的广播比赛不一样的是,在师范里每个节日都会举行丰富多彩的文体活动让学生和老师们一展风采,清明书画展、五四游园活动、五一国庆春节文艺汇演、端午中秋诗歌比赛、还有运动会、篮球赛、读书交流会等等。同学们谈论的也都是《献给爱丽丝》会弹了吗,我的素描还没画完,老师
-
贷款如何查征信?信用查询征信中心为你解答
一、为什么需要查询个人征信?贷款是一种金融行为,而银行或其他贷款机构会对借款人的信用状况进行评估。而征信报告就是展现个人信用状况的重要依据之一。通过查询个人征信,借债人能够了解到自己的信用评级、已有的贷款和逾期记录等信息,这对于贷款成功与否至关重要。二、如何查询个人征信?现在,查询个
-
民生信用卡还款方式,民生信用卡app还款流程
房贷延期适用4种人,咱们上文说到了。今天来看看还有哪些银行有关怀政策■中信银行根据客户需求安排宽限期■江阴农商银行疫情期间设专岗,建立疫情防控期间特殊信贷业务绿色审批通道■上海农商银行提供一定的还款宽限期■招商银行提供还款日变更,存量续贷
-
抵扣券,离谱!买房时赠送的车位抵用券不能用,房开商随手发的,只是张宣传单
2019年,贵阳的冉女士在白云区绿地国际花都买了一套房当时,签完购房合同房产销售还赠送了她一张5000元的车位抵用券可等到交了房冉女士拿着这张抵用券去买车位时却被告知,这券用不了2019年,在朋友的介绍下冉女士来到了绿地国际花都看房。本来还对购房价格有些犹豫的冉女士,在听到销售说购房还赠送车位抵用券后,就爽快地签下了购房合同。冉女士:
-
一百六十万日元等于多少人民币,六十万日元等于多少人民币2021
这个话题还挺适合六月。按照罗马神话,六月(June)得名于婚姻与母性之神朱诺(Juno),据说罗马人有六月结婚的传统说法。可就在这个时节,日本却发布了一项关于婚恋意愿的调查报告,捎带手也把我国去年的结婚登记数据送上了媒体热度榜。数据表现让人皱眉。数据显示,2021年,我国结婚登记数据是763.6万对,首次跌破了800万对大关,还创下了1986年以来的新低。带着一半敬畏一半好奇,我去看